[edit]
DELVE Global COVID-19 Dataset
Prepared for the DELVE Initiative by
Summary
This openly-licensed research-ready dataset consolidates country-level COVID-19 data from multiple sources. It contains cases, deaths, tests, non-pharmaceutical interventions, excess mortality, mobility statistics, weather patterns and other metadata for up to 170 countries.
Citation
(2020), DELVE Global COVID-19 Dataset. Published 02 June 2020. Available from https://rs-delve.github.io/data_software/global-dataset.html.
Introduction
COVID-19 has profoundly impacted the daily lives of more than half of the world’s population. Different countries and cultures have responded to the disease in varying ways, shaped by a dynamic understanding of the pandemic on microscopic and macroscopic scale. The body of data on COVID-19 grows daily, and with it, the scope of possible data-driven conclusions that could be drawn from it. As part of the international effort to collate a common, readily accessible dataset, we created an international dataset that joins data that was derived by DELVE with existing international datasets.
Dataset
The DELVE Initiative is proud to announce the release of a global COVID-19 dataset. This openly-licensed dataset consolidates country-level data on non-pharmaceutical interventions, cases, deaths, tests, excess mortality, mobility statistics, weather patterns and other metadata from multiple sources into a single analysis-friendly format. We hope that this dataset will be useful for data scientists, statisticians, epidemiologists and other researchers who wish to investigate the effects of the international response to the COVID-19 pandemic.
The dataset is available as an automatically generated CSV (updated daily at 11PM UTC) on the DELVE Github repository. Basic exploratory data analysis is provided in a Jupyter notebook. A convenient unified Python API is also available to access the individual underlying source datasets, which may contain more details or finer resolution, as demonstrated in an example notebook.
A full description of the dataset and its fields is available in the Codebook.
Covariates and Sources
Non-Pharmaceutical Interventions (NPIs)
The dataset contains 13 NPIs and 4 economic interventions from the Oxford Blavatnik School of Government’s Coronavirus Government Response Tracker. According to their website: “The Oxford COVID-19 Government Response Tracker (OxCGRT) systematically collects information on several different common policy responses governments have taken, scores the stringency of such measures, and aggregates these scores into a common Stringency Index.” These NPIs are augmented with a “masks” NPI that the DELVE team extracts from the ACAPS Government Measures Dataset, Masks4All as well as publicly available news articles. We deliberately exclude the last 2 weeks of data from the plot below, as the data update cycle makes the most recent data less reliable.
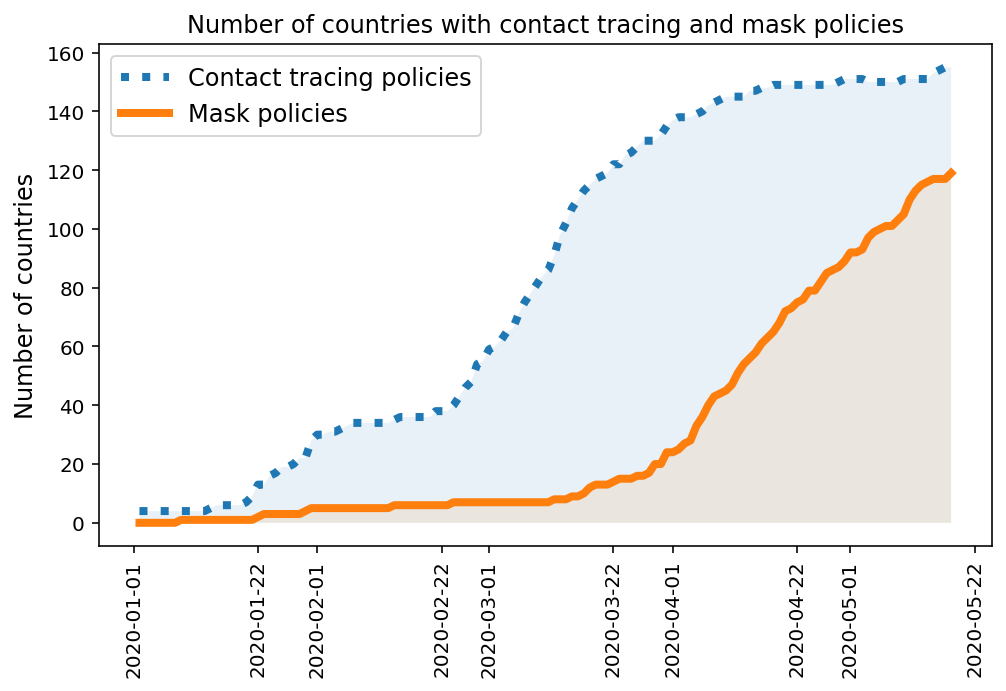
COVID-19 Cases, Deaths and Tests
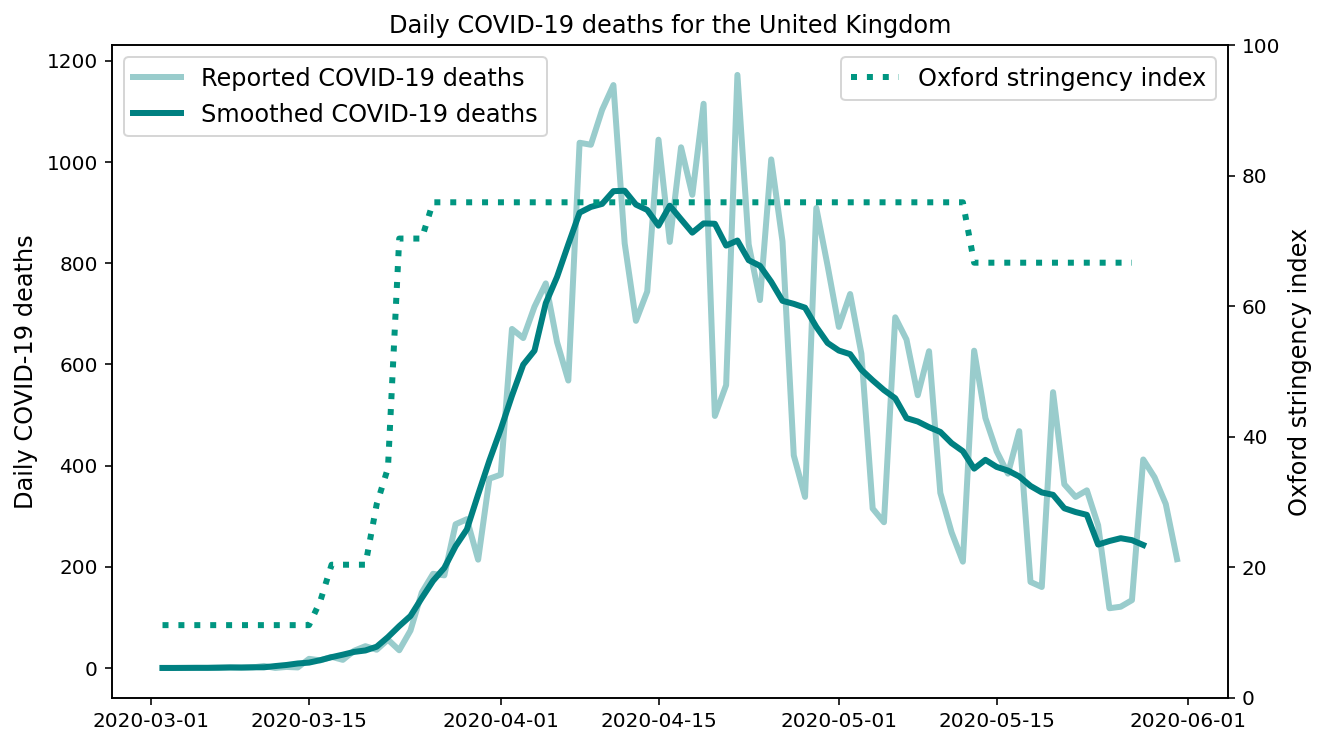
COVID-19 cases and deaths figures come from the European Centre for Disease Prevention and Control (ECDC) who collate these figures not just for Europe, but for countries across the globe. Our World in Data compiles a dataset containing the number of COVID-19 tests performed globally. These data are obtained from numerous news and social media sources. It is important to note that the published data has day of week effects and reporting noise, which is why we plot a rolling 7-day smoothed version of new deaths in the plot below. Comparisons between countries should also be made with caution as different countries have different testing and reporting policies. Data should be normalized to take this into account, for example by comparing rates of change rather than absolute numbers.
Excess Mortality
Using weekly mortality data from the Human Mortality Database and EuroStat, the DELVE team computed excess mortality. This data has been supplemented with pre-computed excess mortality data from The Economist.
Excess mortality is defined here as the difference between the number of deaths occurring in a given week in 2020 and the average number of deaths in the same week in the preceding five (or four, depending on data available) years. In some cases, countries only publish death registration dates rather than occurrence dates.
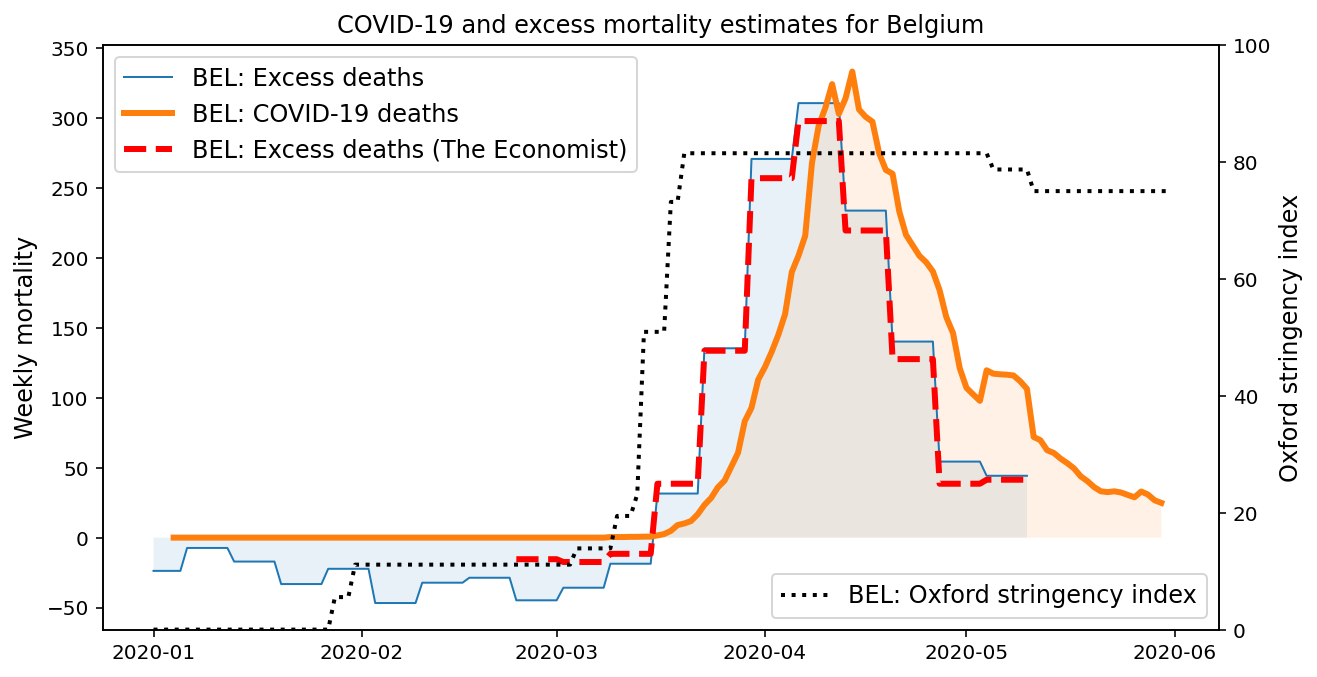
Excess deaths are not subject to different COVID-19 testing rates and classification policies like the official COVID-19 case and death figures, which suggests that they may be more robust. However, modellers should be aware that historical fluctuations are still hidden in these aggregate statistics. We recommend closer investigation as a rule of thumb. Taking Germany as an example, one might (wrongly) arribute a lower than normal excess mortality in the first two months of 2020 to individual precautionary responses to COVID-19.
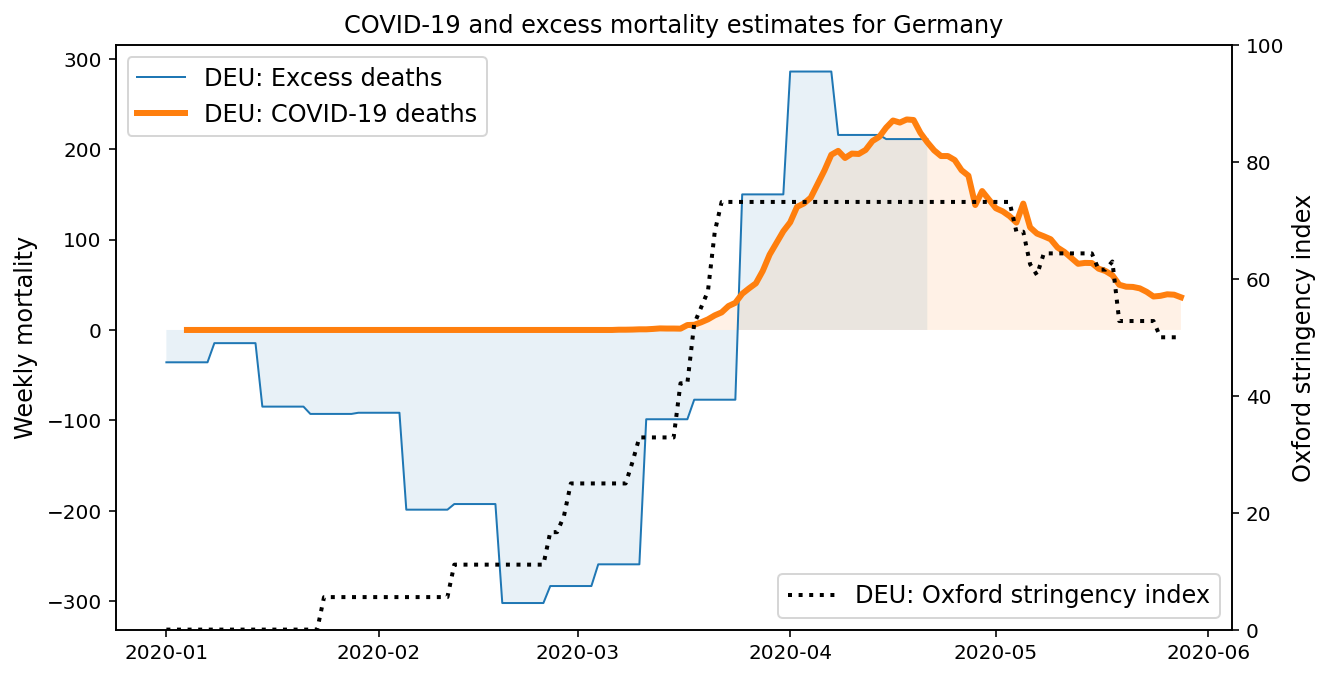
However, seasonal influenza is a major cause of mortality pre-COVID, and past mortality fluctuations sometimes far exceed that of COVID-19. This is evident when we consider the breakdown of Germany’s mortality rates for the four preceding years.
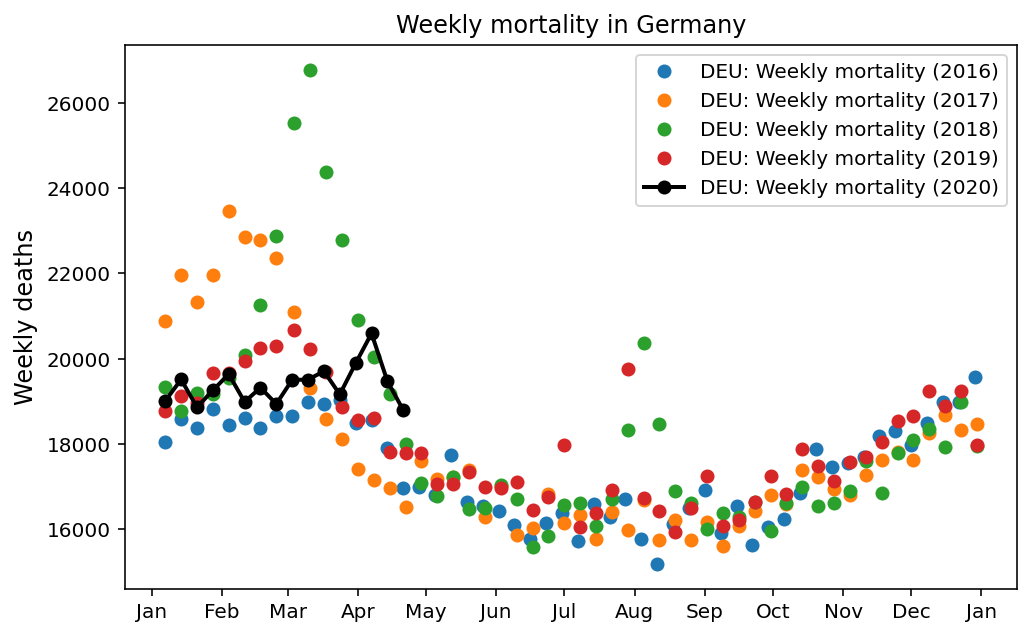
As this example shows, analysis of excess mortality data has to be done with caution to avoid incorrect conclusions. We recommend careful analysis of any trends found in this data.
Mobility Data
The dataset includes 6 fields from the Google Community Mobility Reports, which track trends over time by geography, across categories of Retail and Recreation, Grocery and Pharmacy, Parks, Transit Stations, Workplaces and Residential. There are a further 3 fields covering transport methods (driving, walking and public transit) from Apple Maps Mobility Trends Reports. This data also exhibits day of week effects (for example mobility to parks is higher on the weekend in the UK) and may need to be normalized to take this into account.
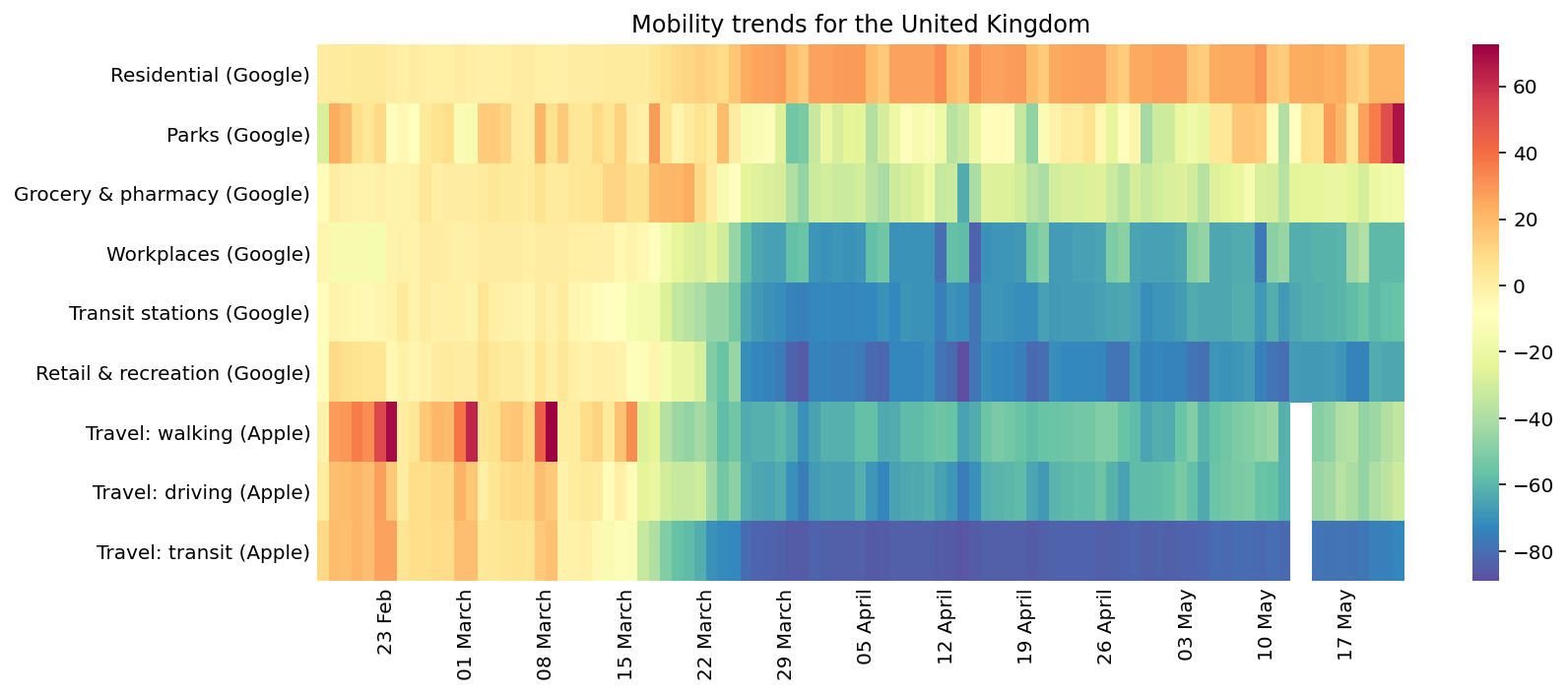
Weather patterns
The dataset includes country-level population-weighted daily averages of the following raw measurements, which were provided by the UK Met Office: temperature (min, mean, max), precipitation, specific humidity, shortwave radiation, and wind speed. Shortwave radiation is used as a proxy for sunshine. The Github repository also contains code for accessing more detailed weather data, such as minimum and maximum values for mentioned metrics.
For each country, on any given day, measurements were averaged across a list of representative major cities, and a weighted average was computed proportionally to population size associated with individual data points. This puts more emphasis on the weather patterns in regions where the chance of COVID-19 transmission is higher.
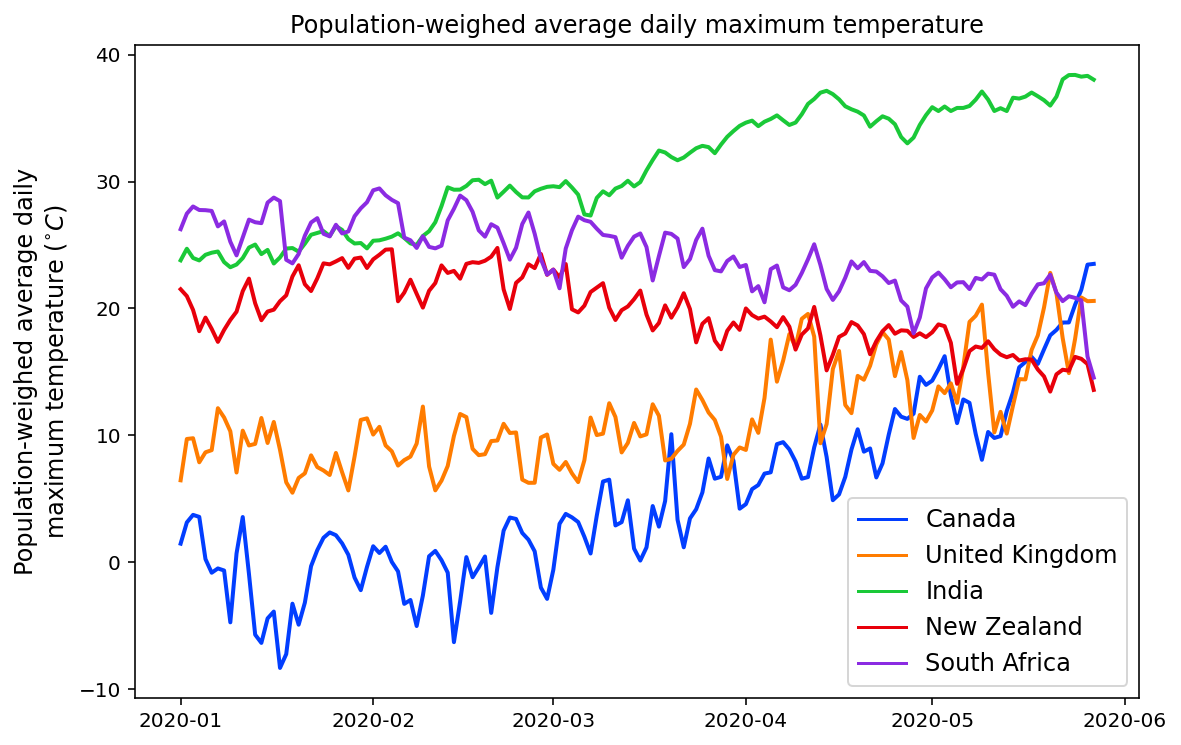
Reference Data
The dataset includes a selection of population-related metadata per country. These fields are static unlike the other time-varying fields. They are obtained from the World Bank Data Bank which aggregates census data from around the world.
Data Quality
Countries are not consistent in how they track and report COVID-19 cases, deaths and tests or in how they collect and aggregate statistics. Inter-country comparisons should therefore be made with caution. There is additional variability in the criteria by which deaths are reported as COVID-19 deaths. Furthermore, recent mortality data are often provisional numbers and may be corrected as death notifications arrive.
Generally, one should assume that the latest week’s data is less reliable than earlier data. This is because certain providers capture data manually and are unable to cycle through every country every day (this applies to the Oxford database and the DELVE masks intervention for example). Not all providers generate data daily (notably mortality statistics and mobility reports).
The DELVE team may add additional fields to the dataset and release fixes to any issues identified over time. Some of the source data providers also perform retroactive updates of their datasets. For these reasons, it is advisable to regularly reload the dataset to pick up the latest changes.
Contributing
We welcome contributions from the community in the form of issues and pull requests on our Github repository.
References
A full list of data sources, licensing and links to original documentation can be found in our data sources documentation.